Running AI directly on my computer without a cloud… Ollama redesigned with Apple-specific technology.
Improved processing speed up to 11 times compared to previous versions… Official support for coding AI agent integration as well.
A Mac with 32GB or more memory is required… Currently focused on supporting the Alibaba Qwen model.

What’s the deal with Ollama?
There are two main ways to use AI: connecting to a server over the Internet, like ChatGPT, or downloading and running an AI model directly on your computer. The latter is called ‘local AI.’
Local AI has the advantage of keeping personal information from being exposed externally and can be used without the internet. This is particularly noteworthy in security-sensitive corporate environments or when handling sensitive information. The problem was that installation and execution were complicated. It was tricky for not only the general public but also developers to handle.
Ollama is a program created to solve this inconvenience. It allows users to download and run AI models on their computers with just one line of command, without complex settings. As a result, it’s become one of the most widely used tools in the local AI field. The version 0.19 released on March 30 is an update that significantly enhances its performance.
The speed has changed… when viewed numerically.
The core of this update is integration with Apple. Ollama 0.19 is newly designed to work on Apple’s machine learning-focused platform, ‘MLX.’ The result of customizing to leverage the unique memory structure of Apple chips has made a noticeable difference in speed.
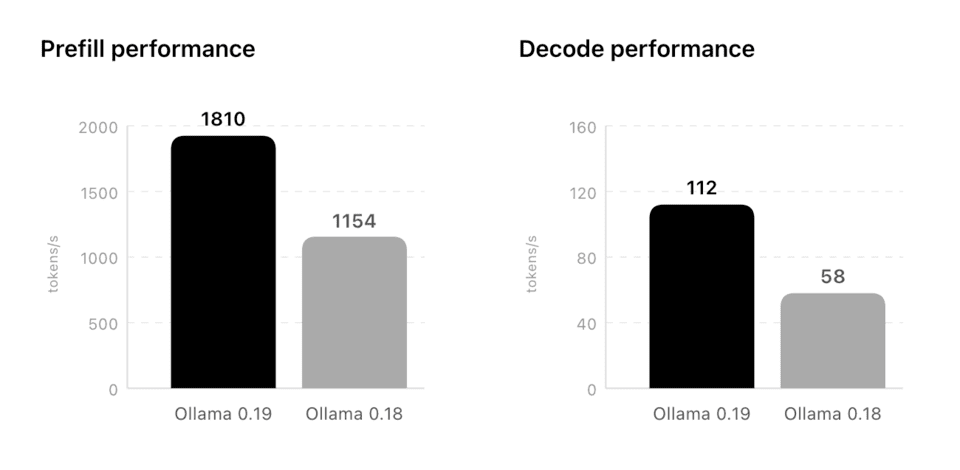
Test results, based on Alibaba’s AI model last month on the 29th, support this. The speed of AI reading and understanding long texts, or ‘pre-fill’ performance, became approximately 11 times faster than the previous version.
Previously, it processed 154 units per second, but the new version processes 1,810 units per second. The speed at which AI generates and displays answers on the screen has also improved by approximately 93% compared to before, from 58 per second to 112.
The latest M5, M5 Pro, and M5 Max chips further increased these figures by using the dedicated computing units embedded in the chips for the first time.
Connecting with coding AI.
Another change that cannot be overlooked in this update is the official integration with coding-specific AI agents. Tools like Claude Code, OpenCode, and Codex are targeted. These tools operate by having AI directly assist developers in writing or correcting code. You can now run these tools on your computer.
One of the technologies that made this possible is improved caching. A cache is a space where frequently used information is stored in advance. Ollama 0.19 has been modified to allow reuse of this cache between sessions. When using tools like Claude Code, which repeat the same basic instructions, memory usage is reduced and response time is improved. A new function that automatically saves in-progress work at important points in a prompt has also been added. Even if part of a previous session is lost, it doesn’t have to be reprocessed from the beginning.
NVIDA’s NVFP4 format support has also been added this time. It is a technology that reduces memory usage and storage requirements while maintaining the accuracy of AI models. This is noteworthy as it allows personal computers to use the same format utilized by cloud service providers in actual operating environments.
It’s not for everyone.
Realistic conditions come with the expectation. To fully harness this preview version, a Mac with 32GB or more of unified memory is required. Unified memory is the shared memory used together by the CPU and GPU, a structural feature of Apple Silicon Macs. This means that running the current flagship model with a basic MacBook Air (16GB) will be difficult.
The supported model is presently limited to Alibaba’s Qwen3.5-35B-A3B. Ollama has announced plans to support more models in the future, but no specific timeframe has been disclosed. The method to bring in user-created custom models is still limited.
That AI runs inside my computer means that information doesn’t leak out to external servers. The essence of this update is the attempt to capture both speed and security simultaneously. Until local AI becomes a practical option rather than just an experiment for some developers, Ollama 0.19 will be recorded as an update that advanced this flow a step further.