Eleven Labs has unveiled a new text-to-speech (TTS) model named ‘Eleven v3 (alpha)’. This model surpasses existing voice synthesis technology by enabling an advanced performance-based voice generation that includes emotional expressions, speaker transitions, and non-verbal sounds.
Eleven v3 greatly enhances the expressive power of voice generation technology through a comprehensive overhaul of its architecture. Users can insert non-verbal tags such as ‘whisper’, ‘laugh’, ‘applause’ into the text, and emotional changes and tone shifts can be naturally implemented even in the middle of sentences. Additionally, it allows speed adjustments, detailed emotion tweaking, and character transition all in a single recording.
Supported languages have expanded from the previous 32 to over 70, covering approximately 90% of the global population. For applications like real-time interactive AI and call centers that require low latency, the existing v2.5 model is recommended, while v3’s streaming feature will be introduced in the future.
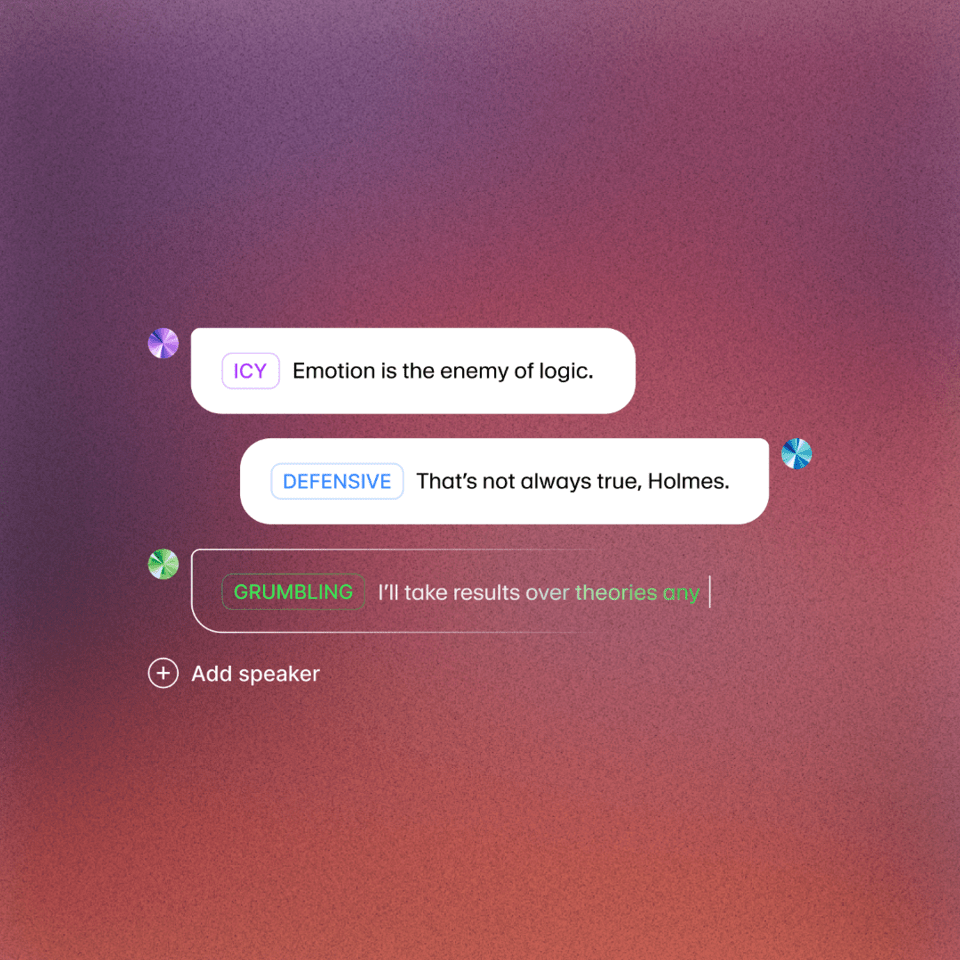
Content creators, interactive media producers, and audiobook makers are the primary users, who can adjust the desired emotions and expressions through detailed prompts. The voice generation, which acts like a real actor, extends AI’s domain as a creative tool beyond mere reading.
The Korean TTS function has also been significantly improved. It can handle special styles such as ‘dialect’ or ‘sports commentary’ in addition to emotional expression, making it highly usable for everything from public institution information delivery to creator content.
Eleven Labs’ CEO, Mati Staniszewski, stated, “v3 is the best TTS model capable of understanding and controlling emotions, expressions, and non-verbal elements,” and emphasized that “this release is an achievement of the leadership of co-founder Piotr Dąbkowski and the team.”