Corporate AI pilot projects are entering an era where 95% stall without results, and what has been holding them back is cost.
A “local-first inference” approach is gaining traction: do the easy work on the device, and send only the hard work to the cloud.
▶ MIT analysis found that 95% of enterprise generative AI pilot projects failed to deliver measurable profit and loss impact. The cause of failure was not model quality, but cost and inability to take root in actual workflows.
▶ Rather than assigning every task to expensive cloud AI, “local-first inference,” which processes what can be handled on-device or on a company’s own servers first, is emerging as a cost-saving alternative.
▶ In one measured case, 70% to 80% of documents were processed locally, cutting cloud costs by 75%. However, it is not a universal solution for every task.
▶ The center of gravity in popular GitHub projects is also shifting away from calling massive models toward on-device execution and cost reduction. This is a trend that directly affects the AI cost burden facing South Korea’s small and medium-sized enterprises and small business owners.

Companies are pouring huge sums into artificial intelligence. The problem is that most of that money is not translating into results.
An analysis released last year by researchers at the Massachusetts Institute of Technology (MIT) sent shockwaves through the industry. It found that 95% of enterprise generative AI pilot projects failed to produce measurable financial impact.
The researchers examined 300 public adoption cases and surveyed hundreds of corporate executives and employees. The amount invested worldwide came to $30 billion to $40 billion, or about 41 trillion won to 55 trillion won. Only 5% of that massive investment produced clear results.
The diagnosis runs counter to common assumptions. The problem, the researchers said, was not AI model performance. The models were smart enough, but they were not being integrated into corporate workflows and were simply consuming costs. In other words, companies were buying expensive smart tools but not using them properly.
Looking at what that “cost” really means reveals the shape of one recently emerging solution. The strategy is to pull AI away from exclusive dependence on the cloud and bring it as close as possible to “my device.”
◆ Does AI drain money the more you use it?
AI usage can be divided into two major stages: “training,” in which vast amounts of data are used to teach a model, and “inference,” in which questions are actually asked of the trained model to obtain answers. In human terms, it is the difference between studying and taking a test. The costs companies pay every day come mostly from the inference stage.
When inference is handled in the cloud, charges are billed by “token.” A token is a bundle of text processed by AI. Every question and every line of response adds to the bill. When only a few employees use it, the cost may seem negligible. But once tens of thousands of customers use it simultaneously and AI is called ten or twenty times in a single task, the bill becomes enormous.
The pricing itself also contains a trap. Major AI companies such as OpenAI, Anthropic, and Google are currently believed to be selling inference services below cost. It is a loss-leading race to attract users. That means the current low pricing may not last forever.
Speed is also a cost. Sending a question to the cloud and receiving an answer can take as long as one to two seconds. For services that must respond instantly, such as real-time translation or voice assistants, this is a fatal weakness. Service outages also frequently occur when usage spikes and call limits are reached.
◆ The solution found “outside the cloud”
The alternative attracting attention is “local-first inference.” The name sounds grand, but the idea is straightforward. Rather than dumping all tasks onto expensive cloud AI, handle easy work first on the device or company server, and send only the truly difficult and ambiguous tasks to the cloud.
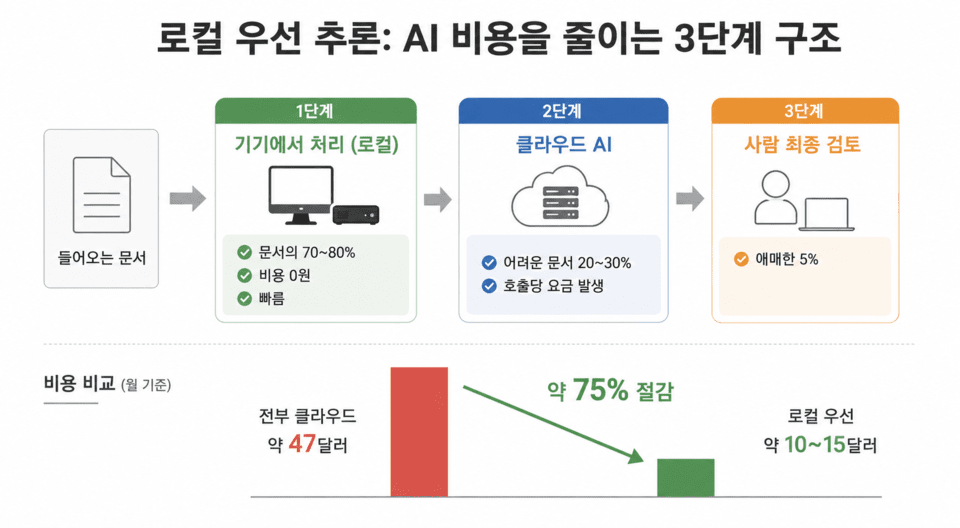
The effect has been confirmed in actual measurements. In one case published by a technology outlet, 4,700 engineering drawing documents were processed, and 70% to 80% of them were automatically filtered out on-device.
There was no need to rely on cloud AI for clear-cut documents. As a result, cloud call costs were reduced by 75%, and processing time by 55%. Documents with ambiguous judgments were sent to the cloud, and risky cases were designed for final human review, helping to contain errors.
There is an important point to note about that 75% figure. It was the result of a specific document-processing task and is not a magical formula that applies to all AI work. Running AI on devices requires hardware purchases, and time from personnel to build and manage the system. For businesses with low transaction volumes, the cloud may actually be cheaper. The key is not “local at all costs,” but deciding according to the nature of the work.
This trend is also visible in developers’ choices. Looking at the 10 fastest-rising projects on GitHub in the third week of May, tools that run directly on devices or reduce the number of calls to save costs stood out more than tools that simply invoke massive models.
Three were built to finish all processing on-device, while another three focused on reducing token consumption itself. This signals a shift in emphasis from massive-model-centered approaches to more refined tools around them.
The change is already built into the smartphones we use every day. Many features that respond instantly, such as call translation and text recognition in photos, do not run on servers across the internet but on the device in your hand.
◆ Questions for companies
The message for companies is clear. For South Korea’s small and medium-sized enterprises and small business owners, the biggest barrier to adopting AI has always been cost. Many have delayed adoption or abandoned pilot projects because they could not afford large cloud fees. That is why the MIT-cited 95% failure rate is not someone else’s problem.
The local-first strategy offers a practical way to lower that barrier. Routine customer questions can be handled on-device or on the company’s own server, while only difficult consultations are assigned to high-performance cloud AI. Because data does not leave the company, it is also advantageous from a privacy standpoint. In fields handling sensitive information, such as healthcare and finance, this matters as much as cost.
Whether cost will remain a permanent burden is another question. Market research firm Gartner predicts that inference costs for models with one trillion parameters will fall by more than 90% by 2030.
That is because device-level chips and model efficiency are improving rapidly. However, the firm also notes that “agentic AI,” which handles multiple steps on its own, uses far more tokens for a single task, so even if unit costs fall, total costs may not decrease easily.
The local-first strategy is not a cure-all either. For small companies, building their own hardware and technical workforce is another burden. Without the ability to design which tasks should be handled internally and which should be sent outside, cost savings could give way to greater system complexity.
The surviving 5% differed at precisely that point. They were the ones that could answer clearly the question of where AI should be inserted into their business processes, rather than simply showing off flashy features.
The center of gravity in the debate over AI costs is shifting from “which model is the smartest” to “when should that model be called.” Success depends less on buying the most expensive tool and more on knowing when to use it. That is the point at which Korean companies must redesign their AI adoption strategy.