The Personal Information Protection Commission has established the first government-level concrete standards on how to safely handle personal information during the development and use of generative artificial intelligence (AI).
On August 6th, at the ‘Generative AI and Privacy’ open seminar, the Personal Information Protection Commission unveiled the ‘Personal Information Processing Guide for Generative AI Development and Utilization.’ This guide aims to clarify criteria under the Personal Information Protection Act throughout the lifecycle of generative AI, thereby reducing uncertainties in practical settings.
The guide divides the generative AI lifecycle into five stages: purpose setting, strategy formulation, learning and development, system application and management, and governance establishment. It systematically outlines legal considerations and safety measures at each stage. For instance, in the purpose setting phase, it is essential to clearly define learning objectives and secure the legal grounds for handling personal information based on its type and source.
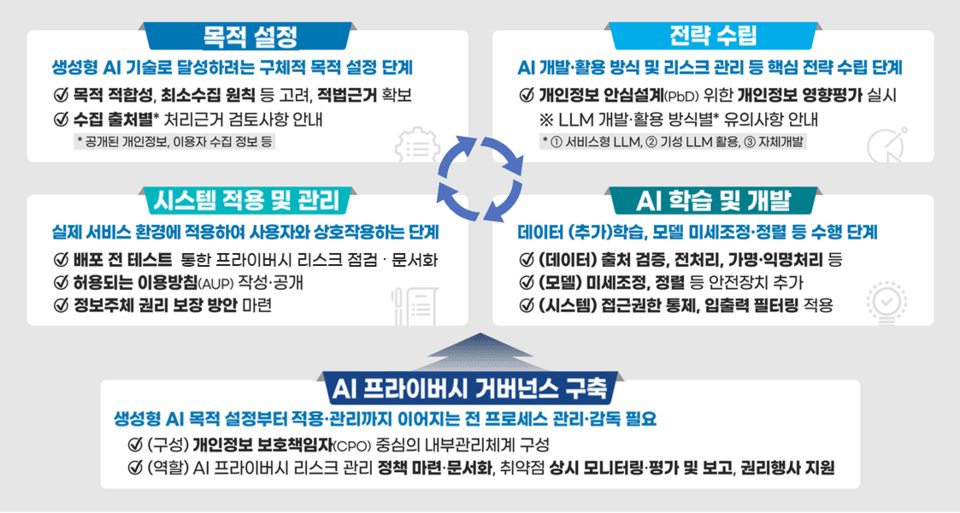
In the learning and development phase, it guides reducing risks such as data poisoning and jailbreak through technical and managerial measures. For the newly emerged search and memory-type AI agents, it recommends implementing control mechanisms to prevent illegal information use and user profiling.
Another key focus of the guide is the criteria on ‘how to handle different types of personal information for various purposes.’ Unlike typical business systems, generative AI processes personal data across multiple phases such as learning, validation, and operation, making interpretations for purposes beyond the original intent complex.
Consequently, the commission differentiates between data sourced from public platforms like the internet (‘public data’) and user data held by companies or institutions. Public data collected online can be used for learning under Article 15, Paragraph 1, Item 6 of the Personal Information Protection Act, provided that the subjects’ rights are not unduly infringed, the data pertains to public interest, and the information subjects can easily request deletion.
In contrast, when companies want to reuse collected user information for AI learning, it’s categorized based on the original purpose as within the current purpose, additional use, or a different new purpose. Decision criteria include the necessity of purpose change, foreseeability, potential infringement of the data subject’s interests, and the level of protection measures. The guide provides practical company use cases to illustrate appropriate decision paths.


The primary feature of this guide is its emphasis on case-based legal interpretations to enhance practical applicability. Reflecting feedback from the field that existing legal interpretations were challenging to apply to the complex scenarios in generative AI development, the commission typified legal issues based on practical technical applications.
For example, it addresses how generative AI development and use models such as API-linked service LLMs (e.g., ChatGPT API), available LLM additions (e.g., Llama open-source model), or self-developed models (e.g., lightweight models) may pose different privacy risks and legal responsibilities. The guide provides protective measures and legal interpretation benchmarks accordingly.
It cites the case of a hospital automating medical record writing through an Enterprise API and explains license selection standards to enhance privacy protections. Furthermore, it advises developers to promptly announce and redistribute improved models if issues arise after development and encourages users to regularly apply patches.
The guide suggests concrete measures to protect information subjects’ rights even after AI distribution. If technical limitations restrict the exercise of traditional rights like accessing, correcting, or deleting data, it recommends transparently informing the reasons and using alternatives like filtering to supplement.
Before distribution, documenting the accuracy of AI results, data exposure risks, and resistance to circumvention to assess risks is advisable.

The guide emphasizes the role of the Chief Privacy Officer (CPO) in embedding personal information protection throughout the generative AI development process. It highlights that the CPO should be involved from the initial planning phase to overall development, forming information protection strategies and conducting ongoing risk assessments like privacy impact assessments and red team tests.
The commission adds that strengthening governance systems and establishing feedback mechanisms between related departments within companies is necessary to ensure that privacy can coexist with innovation.
Ko Haksoo, Chairman of the Personal Information Protection Commission, stated, “This guide will serve as a stepping stone for systematically reflecting on privacy protection in the development and utilization processes of generative AI, resolving legal uncertainties in practice,” emphasizing that they will continue to strive to lay the groundwork for ‘coexistence of privacy and innovation’.
Furthermore, the guide will be continually updated following technological advancements and changes in domestic and international privacy protection policies. Companies, institutions, and startups preparing for generative applications can enhance their self-regulatory compliance capabilities and apply them to practice through this guide.